May 05, 2026
TABular Semantic Enhancement Blueprint (TAB-SEB)
- 1University of Bologna;
- 2University of Helsinki



External link: https://ariannamorettj.github.io/tab_seb/
Protocol Citation: Arianna Moretti 2026. TABular Semantic Enhancement Blueprint (TAB-SEB). protocols.io https://dx.doi.org/10.17504/protocols.io.eq2ly5qrrvx9/v1
License: This is an open access protocol distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited
Protocol status: In development
We are still developing and optimizing this protocol
Created: February 27, 2026
Last Modified: May 05, 2026
Protocol Integer ID: 244123
Keywords: Cultural Heritage (CH), GLAM metadata, tabular-to-RDF conversion, semantic enhancement, interoperability, metadata harmonisation, multidisciplinary digitisation teams, technology-agnostic workflow blueprint, mediated access mechanisms, precompiled queries, tabular semantic enhancement blueprint, semantic web tooling, semantic web technology, benefits of the semantic webare, benefits of semantic web technology, workflow for semantic enhancement, workflow blueprint, semantic webare, full workflow blueprint, rdf materialisation, transferable workflow blueprint, rdf materialisation core, workflow structure, curated tabular layer, quantitative evaluation of the workflow, semantic access layer, data without domain expertise, rdf graph materialisation, tabular data into rdf, supporting documentation, internal organisation of the workflow, multidisciplinary digitisation team, curated table, domain expertise, rdf generation, workflow document, preliminary tabular data preparation, publication of the rdf serialisation,
Funders Acknowledgements:
European Union – NextGenerationEU, NRP Mission 4 Component 2 Investment 1.3, CHANGES
Grant ID: CUP B53C22003780006
Abstract
Overview
- Purpose. The workflow blueprint supports semantic enhancement of Cultural Heritage and GLAM metadata by converting tabular, semi-structured, or externally sourced data into RDF to increase interoperability.
- Secondary aim. It also targets usability: the benefits of the Semantic Webare exposed to stakeholders who do not use Semantic Web tooling directly through mediated access mechanisms (e.g., precompiled queries and web interfaces).
- Intended users (of the workflow blueprint). Multidisciplinary digitisation teams (domain experts + digital humanists/technical staff), with a separation of responsibilities that preserves feasibility in real projects.
- Intended users (of the workflow products). (1) Specialised users (capable of independently interacting and enhancing LOD), (2) domain experts (of the relevant domain for the data, without technical expertise), and (3) general audence (interacting with the data without domain expertise or technical competency)
- Research output framing. The contribution is formalised as a transferable workflow blueprint independent of any specific execution environment; executable implementations are treated as validation artefacts and instantiations.
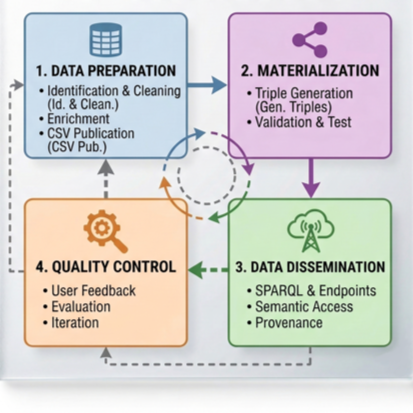
Figure 1. TAB-SEB simplified diagram image
Detailed description:
This section builds on the workflow structure introduced in the methodology chapter, in the subsection Definition of the Workflow’s Main Purpose and Steps Identification. That section established the final high-level architecture: a central core step that converts tabular data into RDF, complemented by an upstream phase for data retrieval and harmonisation via metadata crosswalks, and a downstream phase for publication and dissemination. Here, the complete resulting workflow is presented as the main research output. Each step is examined procedurally, specifying expected inputs and outputs, providing non-blocking tool suggestions, and defining testing and validation practices.
The workflow’s primary purpose is to support the semantic enhancement of cultural heritage and GLAM metadata by enabling the conversion of tabular, semi-structured, and externally sourced data into RDF, thereby increasing interoperability.
A secondary aim concerns usability: the workflow is designed so that the benefits of Semantic Web technologies can be leveraged by stakeholders who do not operate Semantic Web tooling directly, through mediated access mechanisms such as precompiled queries and web-based interfaces built on the resulting graph.
The intended users are multidisciplinary digitisation teams in which domain experts from the humanities and GLAM institutions collaborate with digital humanists and technical staff.
The workflow is structured to separate responsibilities in a way that preserves feasibility in real projects: domain experts contribute modelling-relevant knowledge through collaborative data collection and structured inputs, while technical contributors implement conversion and publication steps without requiring full domain mastery. The expected outputs, therefore, operate at two complementary levels:
- at the data level, workflow execution produces RDF datasets that are openly reusable by technical audiences and suitable for integration into broader Linked Open Data ecosystems.
- and at the access level, the workflow supports the generation of user-facing dissemination layers that expose the same data through interfaces intended for mixed audiences, enabling exploration without requiring SPARQL fluency.
The research contribution is formalised as a workflow blueprint, defined as a transferable operating model independent of any specific execution environment. Executable implementations are treated as validation artefacts and context-specific instantiations. This distinction follows established workflow-publication practices in which the blueprint constitutes the stable methodological contribution, while implementations provide evidence of feasibility and boundary conditions. The blueprint is expressed as a chain of phases and checkpoints, with explicit decision points and traceable deviations, and is designed to support human-in-the-loop reproducibility and iterative refinement. Monitoring, evaluation, and testing are embedded as workflow-native quality-control activities, and intermediate outputs and diagnostics are treated as accountable artefacts rather than incidental by-products.
Operationally, the blueprint is organised into three macro-phases followed by a supplementary evaluation step that enables re-iteration when input data are updated or when output quality requires improvement: preliminary data preparation; conversion to RDF as the core materialisation step; and data dissemination. Each macro-phase is defined by explicit input and output expectations, associated decision points, and integrated quality-control checkpoints to sustain traceability and methodological reliability across heterogeneous domains. The full workflow blueprint is released on Protocols under a CC0 license, where it is kept updated.
The workflow’s general structure, which outlines the main blueprint steps, is illustrated below. A more in-depth analysis of the procedural tasks for each step is available in the workflow document on Protocols. This analysis includes links and examples of specific implementations, the expected inputs and outputs, optional suggestions for tools, and methods for testing and validation.
- Title: TABular Semantic Enhancement Blueprint (TAB-SEB).
- Authors/creators: Arianna Moretti.
- Resource (private link for reviewers): https://www.protocols.io/private/FB400EA3134211F1BB740A58A9FEAC02 (to be removed before publication).
- Partially documented in: Moretti, Arianna. “Defining a Workflow for Semantic Enhancement of Cultural Heritage Metadata.” Proceedings of IRCDL 2026 (CEUR-WS Workshop Proceedings), 2026.
The workflow blueprint is presented here as a versioned and citable, transferable, technology-agnostic but execution-oriented methodological artefact released on Protocols.io, with explicit phases, declared inputs and outputs, decision points, and integrated quality-control checkpoints. Its technical function is to provide a stable coordination layer across heterogeneous implementations by connecting tabular templates, extraction and harmonisation procedures, identifier-enrichment routines, a CSV-to-RDF materialisation core based on mappings, configurations, and functions, and downstream dissemination components such as RDF releases, SPARQL endpoints, semantic access layers, and provenance packages. Within this framework, the blueprint constitutes the persistent methodological research object, whereas the case-study implementations represent step-specific executable instantiations that document feasibility, reuse conditions, and extension points. Below, a summary of the general logic and internal organisation of the workflow is introduced. However, for detailed consultation of the resource in its full workflow dimension, including step-by-step articulation, examples, linked artefacts, supporting documentation, warnings, and implementation-oriented guidance, reference should be made to the Protocols.io release itself.
- The first section of the blueprint covers (1) Preliminary tabular data preparation. (1.1) Input data identification establishes the operational entry point of the workflow by determining whether the project begins from newly collected tabular data or from pre-existing external sources, and by fixing the semantic and procedural assumptions under which later RDF materialisation can remain deterministic. This step includes both the reuse of tabular templates and conventions when data are collected ex novo, and the assessment of alternative access channels and extraction strategies when the workflow starts from external sources. In both cases, and especially where third-party data are reused, it also requires identification of the licence constraints governing reuse, including institutional policies, source licensing terms, rights-holder requirements, and dissemination restrictions. This step also encompasses data extraction and the generation of an exploratory sample dataset, accompanied by monitoring and automated tests, as well as subsequent human inspection and feedback collection aimed at identifying harmonisation needs. (1.2) Harmonisation and cleaning, then curate the tabular layer through header translation, schema crosswalking, unification of heterogeneous exports, value normalisation, separator management for multivalued cells, deduplication, conflict detection, cardinality checks, and identifier validation, producing curated tables, transformation logs, and diagnostic reports. (1.3) Dataset enrichment with persistent identifiers and links to external sources increases linkability, reduces ambiguity, and prepares the dataset for semantic reconciliation. (1.4) Definition of research-oriented requirements and querying desiderata shifts the dataset from a descriptive inventory to a research-oriented data product by formalising the entities, relations, filters, aggregations, and dissemination requirements that the later semantic layer must support. (1.5) Production of purpose-oriented optimised subsets together with traceability artefacts applies where the full dataset is too broad, heterogeneous, or computationally inconvenient for a given analytical purpose. (1.6) Publication of the resulting tabular datasets and complementary materials with persistent identifiers under an open licence turns the curated tabular layer into a stable, citable, and reusable intermediate research output prior to RDF generation.
- The second section encompasses (2) RDF graph materialisation. (2.1) RDF graph generation from curated data covers the conversion of the curated tabular layer into RDF under an explicit target model and mapping strategy. Its inputs include the cleaned tables, the target application profile or data model, mapping files, runtime configurations, and any function libraries or orchestration logic required to handle heterogeneous values, multivalued fields, partial input availability, and graph merging. This step produces RDF serialisations together with execution diagnostics and traceable mapping artefacts. (2.2) Validation assesses the structural and semantic consistency of the generated graph, including checks for duplicate IRIs, type conflicts, temporal inconsistencies, and violations of expected property patterns. (2.3) Testing complements validation through qualitative and quantitative procedures, including code-level checks, runtime and performance monitoring, regression-sensitive diagnostics, human inspection of sample outputs, and feedback-based refinement cycles. Taken together, these steps define the materialisation core as a controlled transformation environment rather than as a single conversion run.
- The third section is dedicated to (3) RDF data dissemination. (3.1) Publication of the RDF serialisation through citable and FAIR-compliant releases stabilises the graph as a persistent research output by depositing the RDF data with versioning, identifiers, and explicit reuse conditions. (3.2) Publication of a SPARQL endpoint provides stable programmatic access to the graph through a queryable semantic service. (3.3) Configuration and publication of a semantic access layer for dissemination addresses the need for mediated access beyond specialist users by enabling website- or portal-based interaction, precompiled queries, navigable views, and public-facing documentation without presupposing SPARQL literacy. (3.4) Integration of a provenance management and change-tracking approach preserves auditability, citability, and interpretability across versions by documenting execution conditions, tracking transformations, and supporting the long-term intelligibility of released data products.
- The fourth and final section concerns (4) Overall quality check. (4.1) User feedback gathering captures adequacy and usability issues emerging across templates, outputs, and dissemination layers. (4.2) Qualitative and quantitative evaluation of the workflow and its outputs consolidates the evidence base generated throughout the process, including validation artefacts, performance reports, output statistics, sample-based inspections, and stakeholder observations, in order to assess both output quality and workflow adequacy. (4.3) Reiteration planning in case of refinement needs or data updates formalises the conditions under which the workflow must be partially or fully re-executed, specifying which phases can be reused unchanged, which artefacts must be regenerated, and which deviations from previous runs must be documented. In this way, the blueprint is not limited to describing a one-off conversion procedure, but functions as a maintainable lifecycle model through which reusable implementations can be attached to specific procedural positions and mobilised as execution-oriented reference artefacts within a single, versioned methodological framework.
Attachments

Image Attribution
Original image created by Arianna Moretti with AI-assisted support from Gemini.
Guidelines
Apply stable identifiers, explicit schema-alignment rules, and version control across inputs, mappings, and outputs. Validate each stage before moving forward and document any deviations introduced by project-specific requirements. Follow the step-by-step suggestions at each stage of the blueprint and consider which alternative approach best suits your research-specific requirements.
Materials
1. Data Preparation: Retrieval, Collection, Harmonisation, Metadata Crosswalking
CHANGES Data Collection Templates and Samples
Title: Modelli Spreadsheet CHANGES - Acquisizione e Oggetti
Authors: Arianna Moretti; Sebastian Barzaghi
Type: Tabular templates and sample datasets
Formats: CSV; ODS
Scope: Object metadata and digitisation-process paradata
Links: Zenodo resource: https://doi.org/10.5281/zenodo.14277219 ; Primary documentation: https://doi.org/10.48550/arXiv.2505.13276 ; Secondary documentation: https://doi.org/10.3724/2096-7004.di.2024.0061
Description: Standardised spreadsheets for collecting exhibition-object metadata and phase-oriented digitisation paradata in CHANGES-related workflows. The deposit combines operational templates and instructional samples so the tabular layer can be reused before RDF generation.
Digital Damaged Ceramics CHANGES Data Collection Extended Templates
Title: Digital Damaged Ceramics – Data Collection Table Templates + CHANGES Field Names Mapping (JSON)
Authors: Arianna Moretti; Madeleine Daste
Type: Extended templates and schema-mapping resources
Formats: CSV; JSON
Scope: Object metadata, process paradata, header-level harmonisation
Links: Documentation and downloads: https://bombedceramics.github.io/digital_damaged_ceramics/documentation.html ; Documentation article: https://doi.org/10.2312/dh.20253375
Description: Project-specific templates translated into an English field vocabulary and paired with JSON mappings from the original CHANGES headers. The package functions as a lightweight schema-translation layer for consistent ingestion and downstream conversion.
OpenCitations Data Sources Converter
Authors: Arianna Moretti; Arcangelo Massari; Elia Rizzetto; Marta Soricetti
Type: Python software and package
Purpose: Crosswalk and preprocessing of heterogeneous scholarly sources into OCDM-aligned tabular outputs
Supported sources: Crossref; DataCite; PubMed; OpenAIRE; JaLC; mEDRA
Licence/runtime: ISC; Python >=3.9,<3.14
Links: PyPI package: https://pypi.org/project/oc-ds-converter/ ; Source repository: https://github.com/opencitations/oc_ds_converter ; Primary documentation: https://doi.org/10.1007/s11192-024-05160-7 ; Secondary documentation: https://doi.org/10.5334/johd.178
Description: Reusable ingestion software that converts multiple bibliographic and citation sources into structured CSV inputs for OpenCitations META and INDEX. Its modular design isolates source-specific logic while reusing shared validation, storage, and normalisation components.
Early Modern BnF Data Collector and Harmoniser
Full title: Early Modern BnF Data Collector and Harmoniser (Actors and Editions Processing, Analysis, and RDF Graph Generation)
Authors: Arianna Moretti; Iiro Tiihonen; Jonas Fischer
Type: Acquisition, harmonisation, analysis, and RDF-generation scripts
Source: Bibliothèque nationale de France SPARQL retrieval workflow
Licence/runtime: MIT; Poetry project, Python ^3.11
Links: Repository: https://github.com/ariannamorettj/Early_Modern_BnF_Harmonisation ; Primary documentation: https://doi.org/10.17504/protocols.io.kqdg31n5zl25/v1
Description: Repository for producing a BnF-derived Early Modern bibliographic dataset and actor layer with explicit harmonisation diagnostics. It combines staged SPARQL retrieval, unification, duplicate analysis, and final RDF graph generation.
2. CSV-to-RDF Materialisation
Morph-KGChad
Full title: Morph-KGChad (Morph-KGC CHANGES Metadata)
Authors: Arianna Moretti; Sebastian Barzaghi
Type: Open-source CSV-to-RDF materialisation pipeline
Target model: CHAD-AP
Core artefacts: YARRRML mappings; INI configuration; UDFs; orchestrator; monitoring; quality checks
Links: Repository: https://github.com/dharc-org/morph-kgc-changes-metadata ; Stable release: https://github.com/dharc-org/morph-kgc-changes-metadata/releases/tag/1.0.1 ; CHAD-AP dependency: https://w3id.org/dharc/ontology/chad-ap/2.0.3 ; Primary documentation: https://doi.org/10.48550/arXiv.2505.13276 ; Secondary documentation: https://doi.org/10.3724/2096-7004.di.2024.0061
Description: Extension of Morph-KGC for reproducible RDF materialisation of CHANGES-aligned tabular datasets. It packages the executable conversion environment needed to generate CHAD-AP-compliant Turtle graphs from object metadata and process paradata.
Morph-KGChad: INI configuration and YARRRML mapping files
Author: Arianna Moretti
Type: Executable configuration release
Contents: 1 INI file and 2 YARRRML mapping files
Scope: Digitisation process data and museum object data
Links: All versions: https://doi.org/10.5281/zenodo.18817813 ; Latest version: https://doi.org/10.5281/zenodo.18817814 ; Primary documentation: https://doi.org/10.48550/arXiv.2505.13276 ; Secondary documentation: https://doi.org/10.3724/2096-7004.di.2024.0061
Description: Versioned deposit of the configuration layer used to operationalise Morph-KGChad. It preserves the exact mapping and runtime artefacts required to reproduce the materialisation workflow transparently.
Morph-KGChad Digital Damaged Ceramics Extension
Author: Arianna Moretti
Type: Forked conversion stack for a project-specific extension
Adaptations: English headers; structural drift tolerance; extended controlled terms; material modelling
Output extension: crm:P45_consists_of
Links: Repository: https://github.com/bombedceramics/morph-kgc-changes-metadata ; Documentation article: https://doi.org/10.2312/dh.20253375
Description: Forked version of the CHANGES conversion pipeline adapted to the Digital Damaged Ceramics data model and documentation choices. It supports translated templates, broader controlled-term coverage, and a pragmatic material-description extension in RDF.
CHAD-ASK: facilitating domain knowledge formalisation in view of LOD conversion
Authors: Arianna Moretti; Sebastian Barzaghi
Type: Survey-to-mapping generation approach and software
Outputs: YARRRML mapping rules and Morph-KGC INI configuration
Environment: Morph-KGChad / Morph-KGC
Documented in: IRCDL 2026 proceedings paper
Links: Questionnaire (all versions): https://doi.org/10.5281/zenodo.18548588 ; Questionnaire (latest version): https://doi.org/10.5281/zenodo.18548589 ; Software: https://github.com/dharc-org/morph-kgc-changes-metadata/tree/main/src/ask-kg
Description: Semi-automatic method that converts structured questionnaire answers into executable materialisation artefacts. It reframes mapping authoring as guided conceptual elicitation so non-RML users can still contribute directly to the conversion setup.
3. Data Publication and Dissemination
Aldrovandi Digital Twin CSV datasets
Title: CSV Datasets on Exhibited Objects and Digitisation Process from “The Other Renaissance - Ulisse Aldrovandi and the Wonders of the World” Temporary Exhibition Digital Twin
Contact persons: Sebastian Barzaghi; Giulia Renda; Arianna Moretti
Type: Versioned tabular dataset release
Layers: CHO metadata and digitisation-process paradata
Links: All versions: https://doi.org/10.5281/zenodo.18184209 ; Latest version: https://doi.org/10.5281/zenodo.18184210 ; Primary documentation: https://doi.org/10.48550/arXiv.2505.13276 ; Secondary documentation: https://doi.org/10.3724/2096-7004.di.2024.0061 ; Related model: https://w3id.org/dharc/ontology/chad-ap/2.0.3 ; Related software: https://github.com/dharc-org/morph-kgc-changes-metadata
Description: Two CSV datasets that function as the tabular input layer for CHAD-KG in the Aldrovandi digital twin workflow. They capture both object-centred description and process-centred provenance in a form designed for direct Morph-KGChad processing.
CHAD-KG: TTL Serialised RDF Dataset of Exhibited Objects and Digitisation Process
Authors: Sebastian Barzaghi; Arianna Moretti
Type: RDF knowledge graph dump
Format: Turtle
Access model: Zenodo release; SPARQL endpoint; static HTML layer
Links: All versions: https://doi.org/10.5281/zenodo.15102845 ; Latest version: https://doi.org/10.5281/zenodo.15102846 ; Primary documentation: https://doi.org/10.48550/arXiv.2505.13276 ; Secondary documentation: https://doi.org/10.3724/2096-7004.di.2024.0061 ; Underlying model: https://w3id.org/dharc/ontology/chad-ap/2.0.3 ; Generation software: https://github.com/dharc-org/morph-kgc-changes-metadata
Description: RDF dump generated from the Aldrovandi tabular datasets through Morph-KGChad and expressed in CHAD-AP. It integrates object description and digitisation-process paradata into a FAIR-oriented, versioned semantic publication.
OpenCitations Index (INDEX) — Citation Dataset + Provenance Dataset
Author/maintainer: OpenCitations
Type: Large-scale open citation and provenance dataset
Licence: CC0
Distributions: CSV; N-Triples; Scholix; website services
Additional 2026 dumps: RDF dump 31306081; RDF dump 31353691; data-source N-Triples 24427051
Links: Citation CSV: https://doi.org/10.6084/m9.figshare.24356626 ; Citation N-Triples: https://doi.org/10.6084/m9.figshare.24369136 ; Citation Scholix: https://doi.org/10.6084/m9.figshare.24416749 ; Provenance CSV: https://doi.org/10.6084/m9.figshare.24417733 ; Provenance N-Triples: https://doi.org/10.6084/m9.figshare.24417736 ; Service entry point: https://opencitations.net ; SPARQL endpoint: https://w3id.org/oc/index/sparql ; REST API v2: https://w3id.org/oc/index/api/v2 ; LUCINDA repository: https://github.com/opencitations/lucinda ; Primary documentation: https://doi.org/10.1007/s11192-024-05160-7
Description: Open citation database distributing citation links and associated provenance as public dumps and query services. The chapter records both the article-based snapshot and the later updates documented on the official download pages.
Digital Damaged Ceramics - RDF and CSV Dataset
Authors: Madeleine Daste; Arianna Moretti
Type: Curated research dataset
Formats: CSV; Turtle
Versioning: Preserved with provenance tracking
Links: All versions: https://doi.org/10.5281/zenodo.15854368 ; Latest version: https://doi.org/10.5281/zenodo.15854369 ; Documentation article: https://doi.org/10.2312/dh.20253375
Description: Versioned release of the Digital Damaged Ceramics dataset in both tabular and RDF serialisations. It serves simultaneously as a reusable dissemination output and as a reference instance aligned with the project’s extended CHANGES-derived templates.
Digital Damaged Ceramics website toolchain and reproducibility package
Title: Digital Damaged Ceramics - website files, data analysis files, and website generation software (1.0)
Authors: Arianna Moretti; Madeleine Daste
Type: Website codebase and reproducibility package
Key pages: index.html; sevres.html; mic.html; sparql.html; 3d.html; dataset.html; documentation.html
Licence: MIT for code; CC BY for dataset distributions on the website
Links: All versions: https://doi.org/10.5281/zenodo.15855787 ; Latest version: https://doi.org/10.5281/zenodo.15855788 ; Website: https://bombedceramics.github.io/digital_damaged_ceramics/ ; Code repository: https://github.com/bombedceramics/digital_damaged_ceramics ; Documentation article: https://doi.org/10.2312/dh.20253375
Description: Package containing the website codebase, data-analysis assets, and semi-automated site-generation materials used for project dissemination. It doubles as a reusable template for similar catalogue-based museum projects.
4. Quality Control and Assessment
Aldrovandi Digital Twin FAIRness assessment matrix
Full title: Aldrovandi Digital Twin - FAIRness assessment matrix (3-level model for heritage collections; adapted application)
Authors: Sebastian Barzaghi; Alice Bordignon; Bianca Gualandi; Ivan Heibi; Arcangelo Massari; Arianna Moretti; Silvio Peroni; Giulia Renda
Type: Assessment matrix
Location: Table 2 in the Data Intelligence article
Function: Reusable evaluation pattern across objects, object-level metadata, and metadata records
Links: Table resource / documentation: https://doi.org/10.3724/2096-7004.di.2024.0061
Description: Compact evidence table adapting an existing heritage-oriented FAIR rubric to the Aldrovandi Digital Twin case. It is included as a reusable quality-control pattern for auditable, cross-case comparison of implementation choices.
Safety warnings
No laboratory hazards apply. Users should verify input-table consistency, identifier policies, mapping versions, and publication settings before execution, since errors in tabular structure, schema alignment, or configuration files may propagate through RDF materialisation and dissemination.
Ethics statement
No animal experiments are involved in this protocol. Therefore, approval from an Institutional Animal Care and Use Committee (IACUC) or equivalent ethics committee is not required.
Before start
Before starting, users are advised to read the protocol description in order to contextualise the workflow blueprint, consult the supporting website linked to the protocol, and review the materials listed in the Materials section. Together, these resources provide the technical and documentary context needed to interpret the workflow and its connected implementations.
Preliminary tabular data preparation
Input data identification
Data gathering (in case of a dataset to be created from scratch)
Data collection13 steps
(in case of a dataset to be created from scratch)
Dataset selection (in case multiple access approaches are provided by a data
source)
- Data extraction and production of a sample dataset for explorative
purposes, accompanied by monitoring and automated tests;
- Human inspection of the sample dataset and feedback to identify
harmonisation needs.
Identification of the legal and ethical constraints to the reuse of collected data
We launch the code from the command prompt, by calling the main function, i.e.: invalid_dois_main with its three required parameters:
- an integer number, defining after how many processed lines of the input file the obtained data are to be saved on the cache files;
- an input file, which should be a csv file with the aforementioned structure, i.e.: two-columns, the first of which, "Valid_citing_DOI", containing the citing identifiers, and the other, "Invalid_cited_DOI", containing the addressed DOIs.
- an output json file, where the processed data will be saved at the end of the process.
RDF graph materialisation:
RDF graph generation from curated data
validation
testing
RDF data dissemination
Publication of the RDF serialisation (e.g., TTL) citable release, through FAIR-compliant platforms
Integration of a provenance management and change tracking approach
Publication of a SPARQL endpoint
Configuration and publication of a semantic access layer for data dissemination, such as a
web portal, that enables data access for both experts and general users;
Overall quality check
User feedback gathering
Qualitative and quantitative results evaluation
Reiteration planning in case of refinement necessities or data updates